В данной заметке анонсируются некоторые
результаты, полученные с использованием нового подхода к моделированию
поведения нейронных сетей. В качестве тестовой
использована вариация задачи, предложенной в статье [1]. Агент получает
вознаграждение при попадании на белый круг при условии, что предварительно он
побывал на черном круге. Вознаграждение, получаемое на белом круге,
лимитировано двумястами тактами времени. Таким образом, наилучшая стратегия
поведения агента заключается в периодическом перемещении от черного круга к
белому и обратно.
Разработанный подход основан полностью на
парадигме нейронных сетей. Используемая нейронная сеть состоит из 100 нейронов.
В отличие от [1] входные нейроны получают
непосредственно информацию о положении агента. Два нейрона выхода отвечают за
перемещение агента в двух различных направлениях.
На представленных рисунках
показано поведение агента в различные моменты процесса обучения после 50000,
100000, 150000 тактов соответственно.
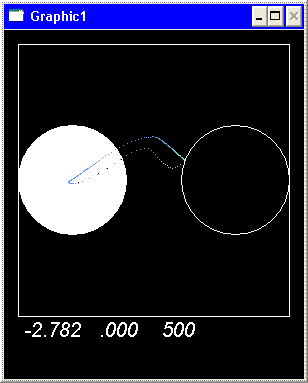
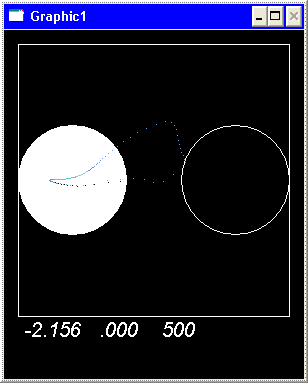
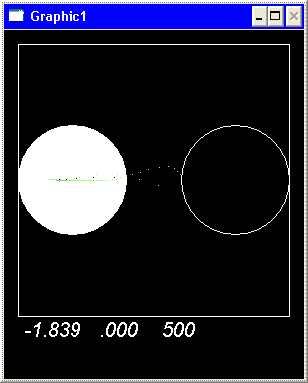
В поведении агента в
процессе обучения наблюдаются две основных линии: исследование выделенного
пространства и использование накопленных знаний. Наблюдается явление перемежаемости, то есть периодическая смена одного режима
другим.
Ниже показано поведение
агента после 100000 тактов в двух других реализациях.

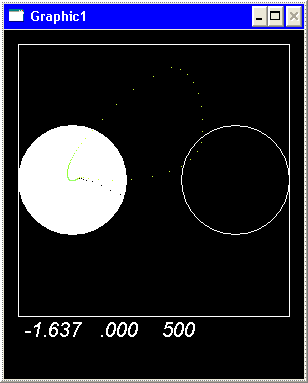
[1] Stefano Nolfi, Dario Floreano.
(2002) Synthesis of autonomous robots through evolution.
TRENDS in Cognitive Sciences Vol.6 No.1